
サーバー監視ツール「munin」の各グラフの意味と読み方。
muninをインストールすると標準でたくさんのグラフが出力されます。中には聞いた事もない単語のグラフもあり、
「いったいこれは何なのか」と疑問に思っていたので調べてみました。
グラフはすべてplugin (/etc/munin/plugins) の内容から出力されていて、さらにそのほとんどが単なるperlスクリプトやシェルスクリプトでした。このpluginが実際はどのようなコマンドを使った結果なのかを確認しながら調べました。プログラムにはあまり明るくない&英語が苦手、なので意味違いしている可能性がありますのでお気づきの点がありましたらコメントを頂けると嬉しいです。
使用したmuninバージョンは1.4.5です。
ほとんどの値は /proc/以下から参照されているようで以下のページがとても役に立ちました。
Man page of PROC – http://linuxjm.sourceforge.jp/html/LDP_man-pages/man5/proc.5.html
disk
Disk IOs per device
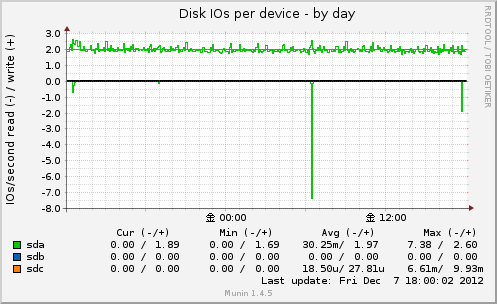
IO使用率(Disk utilization per deviceで得た値)を単位時間内で行ったI/O数で分割し
1秒間で行ったI/O数の平均値を出力します。
グラフを見てると入出力したkbyte数も出力してくれるようです。
実体は /proc/diskstats の出力内容から。
ファイルには各ディスクデバイスのディスク I/O 統計情報が書かれていて、
詳細は以下のカーネルドキュメント。
http://www.kernel.org/doc/Documentation/iostats.txt
各項目の意味はこちらが詳しいです。
Disk latency per device
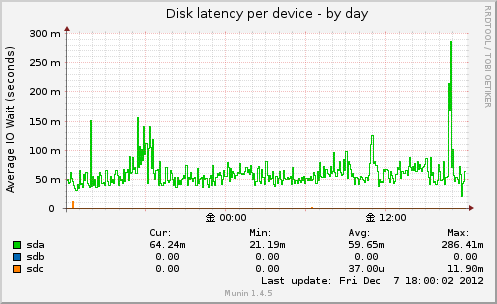
こちらのグラフもTOPページで全ディスクの読み書きにかかる時間を表示、
クリックで、各ディスクごとの読み書きにかかる時間を表示します。
この時間はsyscallがアプリケーションとデバイスを行き来する平均時間から算出されている?みたいです。
単位はミリセカンド(1000分の1秒)。
実体は /proc/diskstats の出力内容から。
Disk throughput per device
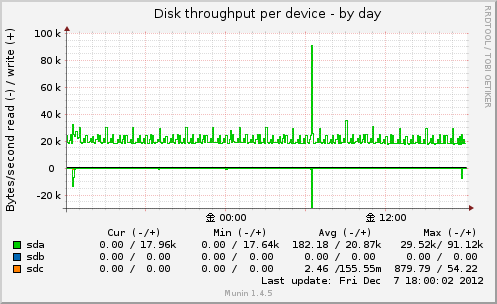
1秒間に読み書きしたバイト数を表示します。
Disk usage in percent
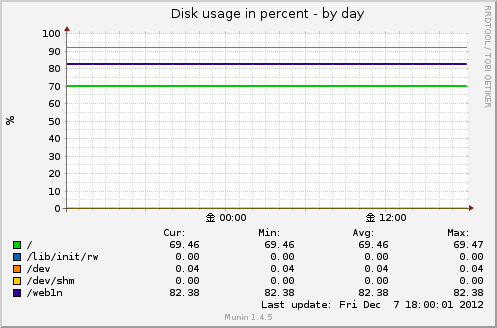
ファイルシステムごとのディスク使用率を%で表示。
元コマンドはdfコマンドです。
Disk utilization per device
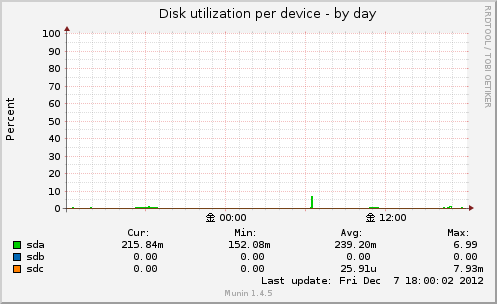
こちらのグラフはTOPページで全ディスクのIO使用率を表示、
クリックで、各ディスクごとのIO使用率を表示します。
LinuxではI/Oリクエストの発生中は1ミリセカンドごとにインクリメントするカウンターを使っています。
もしこのカウンターが1秒の間に1000msecぶんインクリメントされるとI/Oリクエストの発生が100%とほぼ近い値になります。
このプラグインは上記の考えからディスクへのIO使用率を%にて提供してくれます。
ただ5分ごとの計測なので当然、瞬間的な表示の取得はできません。
実体は /proc/diskstats の出力内容から。
Inode usage in percent
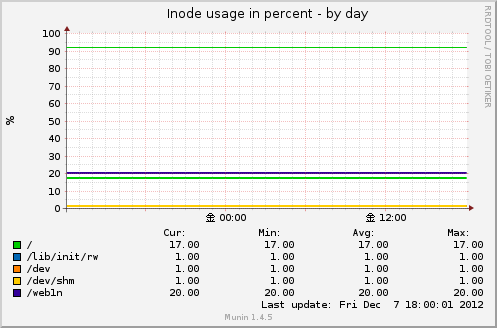
ファイルシステムごとのinode使用率を%で表示。
元コマンドはdfコマンドです。
IO Service time
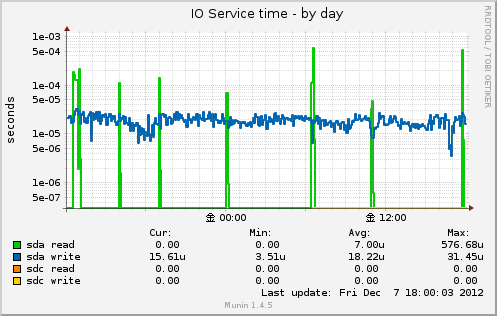
デバイスごとの書き込み/読み込みの遅れをグラフ化してくれます。
書き込み/読み込みにかかった時間を成功回数で割った時間です。
左メニューの le-05 などは10の-5乗という意味。
つまりこのグラフが大きければ大きいほどIOがヤバイという事になります。
実体は上記と同じく /proc/diskstats の出力内容から。
・読み込みが成功した回数
・読み込みにかかった時間 (ミリ秒)
・書き込みが成功した回数
・書き込みにかかった時間 (ミリ秒)
の値を取得し前回取得した数の差分を求めて計算する事でグラフ化されています。
IOstat
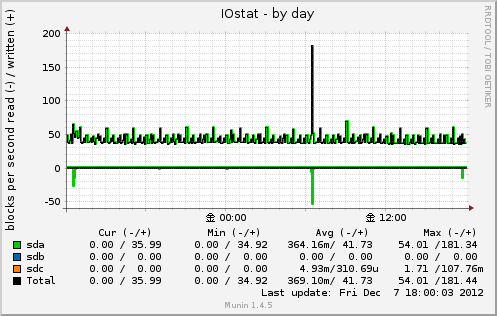
デバイスごとの書き込み能力をグラフ化してくれます。
こちらは表示の仕方が特殊で1秒間に読み書きに成功したセクタ数が出力されています。
グラフの+項目が書き込み、-項目が読み込みの値となっています。
実体は /proc/diskstats の出力内容から。
munin
Munin processing time
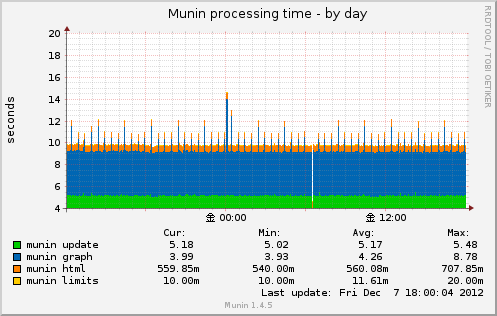
プラグイン munin_stats
muninがデータを取得し、グラフ、html出力など、4つの作業ごとにかかった時間を出力します。
network
Connections through firewall
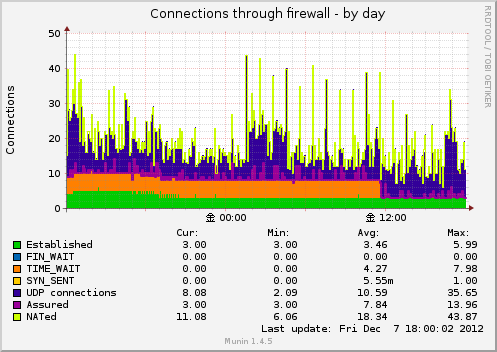
iptables を使うとき, ip_conntrack というテーブルで tcp のセッションを管理しています。
iptablesを通ったパケットは現在の接続状態などを上記のテーブルへ記録します。
このプラグインではそのテーブルを参照し、現在の状態別の接続数を表示してくれます。
ESTABLISHED
TCPコネクションが確立して通信している状態
FIN_WAIT
終了を宣言した状態
TIME_WAIT
コネクションの終了待ち状態
SYN_SENT
SYNを送信した状態。
UDP_Connections
UDPコネクション数
Assured
ASSUREDフラグの数。
このフラグは
NATed
NATの数?詳細はちょっとわからなかったです。
実態は以下のコマンドで出力される内容です。
cat /proc/net/ip_conntrack
参考
conntrackエントリ – http://www.asahi-net.or.jp/~aa4t-nngk/ipttut/output/theconntrackentries.html
eth0 errors
パケットのエラー数を計測します。
基本的にインターフェイスにてエラーパケットが1でも存在すれば設定や接続先のハブに問題がなければ
個人的には信頼できないNICとして交換を視野に入れます。
実態は以下のコマンドで出力される内容です。
cat /proc/net/dev
eth0 traffic
パケットの転送料を計測します。
ethtoolにてNICの接続状態やリンクモード(100Mbpsとか1000Mbpsとか)を取得し、
/proc/net/devの値を取得しています。
inがマイナス、outがプラスとしてグラフ出力されます。
Firewall Throughput
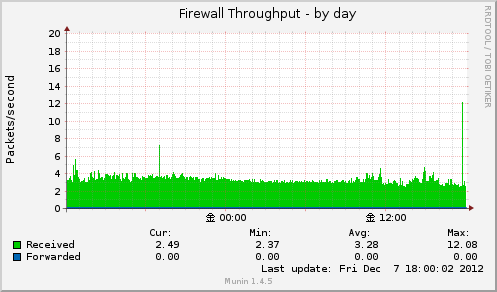
プラグイン fw_packets
1秒間に転送したパケット数を表示します。
/proc/net/snmp のIP:行の値を取得してこちらの値を元に計算されています。
HTTP loadtime of a page
プラグイン http_loadtime
http://localhost/ をwgetにて取得、その時間をtimeコマンドで取得し表示します。
任意のURLへ変えたい場合は、プラグインの以下の部分
[code]
target – URL to fetch (default: “http://localhost/“)
[/code]
を変更すれば可能だと思います。
ipconntrack
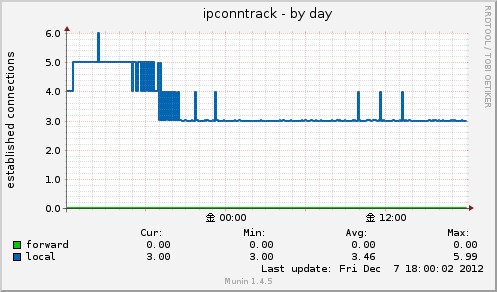
iptables を使うとき, ip_conntrack というテーブルで tcp のセッションを管理しています。
接続数が増えると、それだけip_conntrackテーブルを使用するのですが、
これがいっぱいになると以下のようなログが出て通信がまったく出来なくなる状態となります。
[code]
ip_conntrack: table full, dropping packet
[/code]
このグラフでは現在のip_conntrackの上限値と使用数を表示してくれます。
実態は /proc/sys/net/ipv4/netfilter/ip_conntrack_max に記述されている値(上限値)と
/proc/net/ip_conntrack の値(現在の使用値)です。
中規模〜大規模なサイトだとこの値は意外と問題となってきますので、使用率があがってきたら
メモリと相談しながら上限をあげたり対策を行いましょう。
参考
iptables の ip_conntrack の最大値を変更する方法 – http://www.sssg.org/blogs/naoya/archives/1454
process
Fork rate
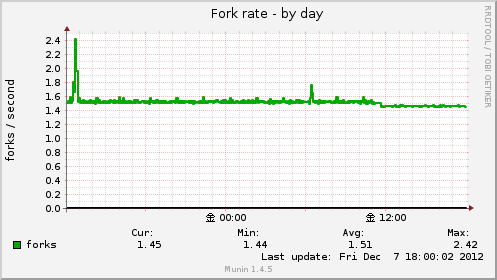
1秒間にfork(プロセスのコピーを生成する事)された数を表示します。
/proc/stat の値の processes 行(プロセスやスレッドが作成された数)の値を取得しています。
Number of threads
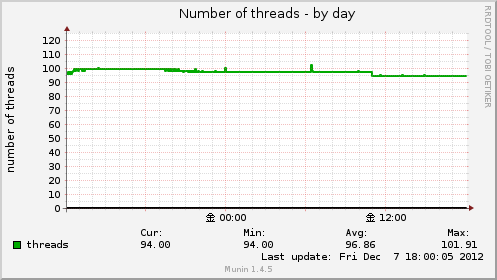
スレッドとは一つのプロセスの中で平行に処理を行いたい場合などに使用されます。
このグラフではスレッドがシステム全体でいくつ作られたスレッド数を表示します。
/proc以下にあるプロセスIDのディレクトリからThreadsの値を取得した合計値です。
実際には以下のようなコマンドで表示されていました。
grep -s ‘^Threads’ /proc/[0-9]*/status
Processes
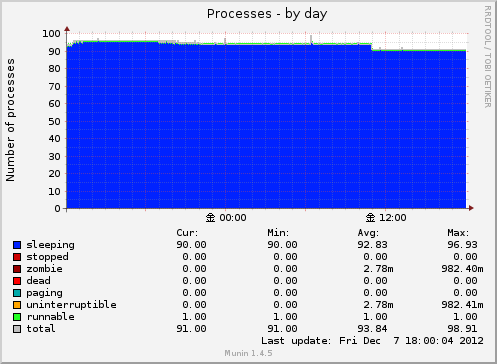
プラグイン processes
プロセスの総数をそれぞれの状態別に表示してくれます。
実態はPSコマンドです
ps –no-header -eo s
Processes priority
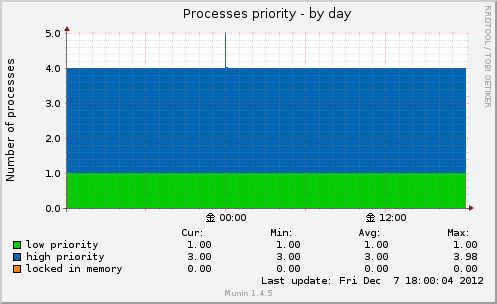
プロセスの優先度ごとの数を表示します。
元コマンドはpsでstat項目の内容で判断しています。
< 優先度高 (high-priority)
N 優先度低 (low-priority)
L メモリーロックプロセス (locked)
として集計されています。
VMstat
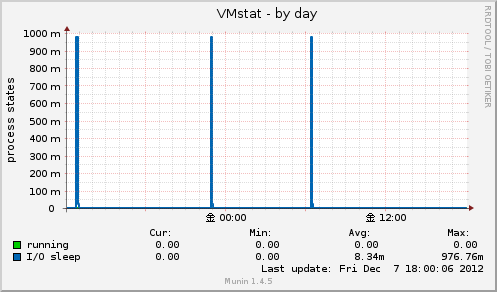
プラグイン vmstat
実行中であるプロセス数、スリープ状態にあるプロセス数をグラフ表示します。
vmstatコマンドのproc行にあるrとbの値をそれぞれ取得しています。
r:実行待ち状態にあるプロセス数
b:割り込み不可能なスリープ状態にあるプロセス数
rは実行可能でCPUの割当をまっている状態のプロセス数なのでグラフではrunningと表示されていますが、実際には実行中ではないような気がします。
この値はロードアベレージとほぼ同じ値を示します。
bはスリープ状態にあるプロセス、、ですがほとんどの原因はI/O待ちで、I/O待ちプロセス数と言い換える事ができます。
System
Available entropy
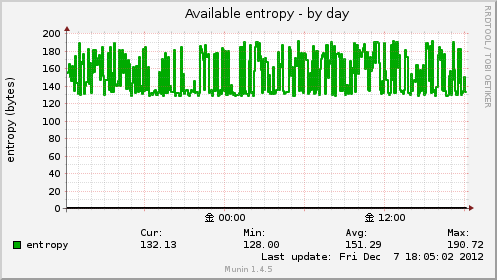
エントロピー(entropy)は乱雑さを意味します。
主に鍵ファイルの生成などランダムな文字列を作成する時に使用されます。
通常はマウス操作などで自動的に乱数が作成されますが、サーバーの場合は付けっぱなしのまま置く事も多いので
このエントロピーが徐々に枯渇していき、乱数発生の際などに極端に動作が遅くなる事があります。
通常は3000とかくらいまであればいいんですが、仮想サーバーだと思うように溜まらないようです。
今の所問題になるほどの遅延は発生していませんがVMWareやさくらのVPSとかで150程度。
物理サーバーだと3000くらいはすぐに溜まります。
使用可能なエントロピーの値は以下のコマンドで取得でき、グラフ生成も以下のコマンドで行われています。
cat /proc/sys/kernel/random/entropy_avail
CPU usage
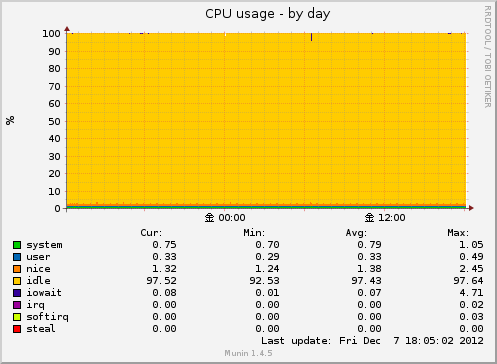
CPUの使用率を表示します。
コア数ぶん表示するので、例えばコア2、ハイパースレッディング対応の場合はMAXが400%となります。
system
システムモード
user
ユーザモード
nice
低い優先度のユーザモード
idle
未使用の状態
iowait
I/O の完了を待っていた時間
割り込み処理を行った時間
softirq
ソフト割り込みの処理を行った時間
steal
仮想化環境での動作時に他のオペレーティングシステムにより消費された時間
guest
Linux カーネルの制御下のゲストオペレーティングシステムの仮想 CPU の 実行に消費された時間
基本的には system user iowaitの値を確認します。
システムモードはOSコードやデバイス・ドライバなどで使用された基本的にはOSで使用されるCPU使用
ユーザーモードはPHPとかApacheなどのユーザーアプリでのCPU使用
iowatiはHDDへの書き込み/読み込み待ち状態のCPU使用
です。
このプラグインが使用している値は /proc/stat のCPU項目です。
File table usage
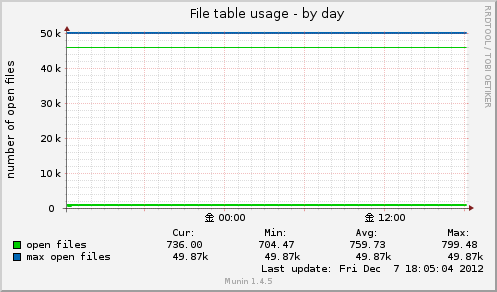
オープンされているファイル数とシステム中のオープンファイル管理データの最大数をグラフ化します。
上限値は /etc/security/limits.conf で変更可能
fs.file-max = 90000 など
取得もとは以下の値です。
/proc/sys/fs/file-nr
Individual interrupts
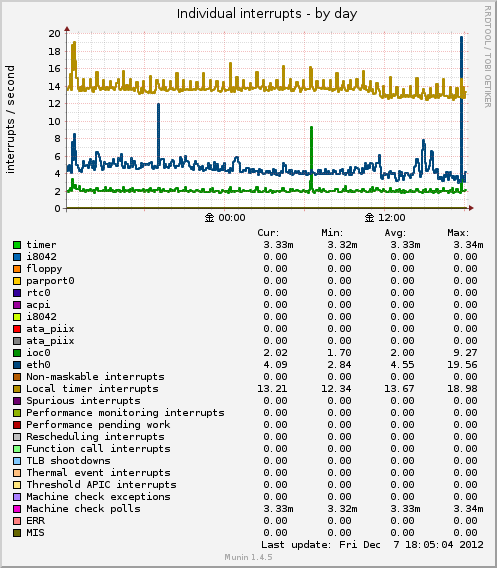
様々な種類の割り込みの数をグラフ化してくれます。
割り込みの種類はマウスとキーボード(i8042)、イーサネット(eth0)などのハードウェアから生じる割り込みや
カーネルからくる割り込みなど様々な種類があるみたいです。
取得元は /proc/interrupts です
Inode table usage
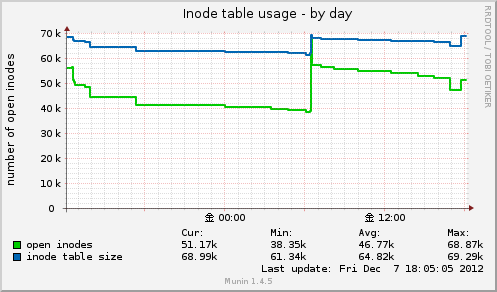
システム中のメモリiノードの数および使用中のメモリiノードの数をグラフします。
取得元は /proc/sys/fs/inode-nr の値です。
Interrupts and context switches
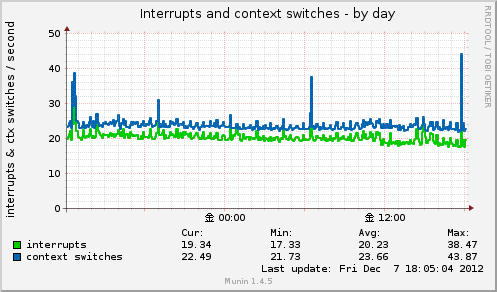
処理された割り込みの回数とコンテクスト・スイッチ(CPUの状態を保存したり復元したりした回数)を表示する。
取得元は /proc/stat の intr および ctxt の値。
Load average
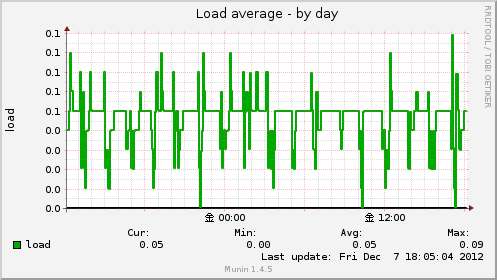
ロードアベレージの値をグラフしてくれます。
取得元は /proc/loadavg で
cut -f2 -d’ ‘ < /proc/loadavg
として取得されているので5分平均の値です。
Logged in users
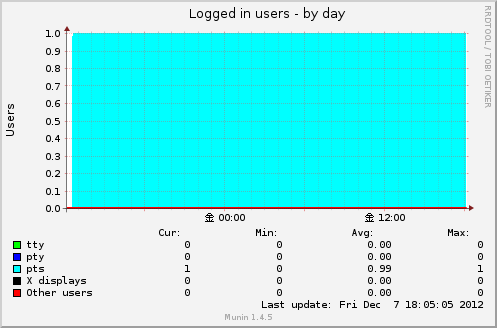
プラグイン users
ログインしているユーザー数を表示します。
取得元はwhoコマンド
Memory usage
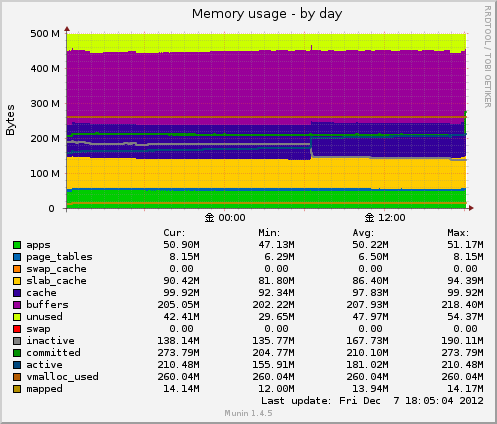
メモリーの使用状況をグラフに表示してくれます。
apps
ユーザアプリ使用メモリサイズ
MemTotal – MemFree – Buffers – Cached – Slab – PageTables – SwapCached
page_tables
ページテーブルエントリという「ページ」の管理構造体として利用されているメモリ
swap_cache
物理メモリ上にキャッシュされたスワップページの総容量
vmalloc_used
vmalloc()で確保された物理メモリ領域とMMCONFIGで確保しているメモリ領域の総容量
slab_cache
スラブアロケータで使用されている物理メモリの総容量
cache
ファイルデータのキャッシュなどに使用している物理メモリの総容量。共有メモリは Cached に加算される。SwapCachedは含まない
cache-(SwapCache+buffers)
buffers
ファイルなどのメタデータとして使用している物理メモリの総容量
unused
未使用のメモリ。
swap
スワップとして使用されている量
SwapTotal – SwapFree
committed
全プロセスによって確保された仮想メモリの総容量。
mapped
ページテーブルに登録されている物理メモリの総容量
active
最近アクセスした物理メモリの容量
inactive
最近アクセスしていない解放してよい物理メモリの容量
取得元は /proc/slabinfo と /proc/meminfo
Swap in/out
1秒間にswap in/outされたブロック数を表示、
取得元は /proc/vmstat の pswpin / pswpoutの値です
Uptime
パソコンが起動してから現在までの時間。
取得元は /proc/uptime
