
こんにちは、クラウドソリューション事業部の本田です。
DynamoDBを使ってアプリケーションを構築する中で
溜まってきたデータを使って利用状況や傾向を可視化したい、そんな時ありますよね。
今回は、AWS AthenaのFadarated Queryという機能を使い、DynamoDBのテーブルのデータを抽出し
Athenaで抽出したデータを、Quicksightで可視化するということをやってみます。
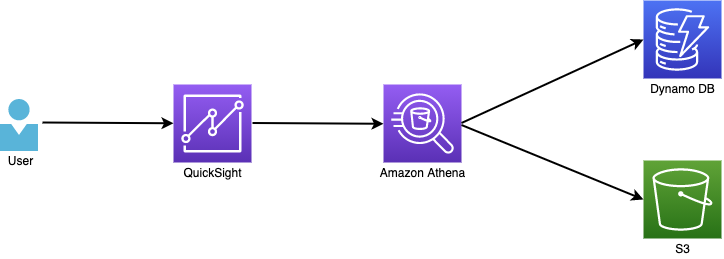
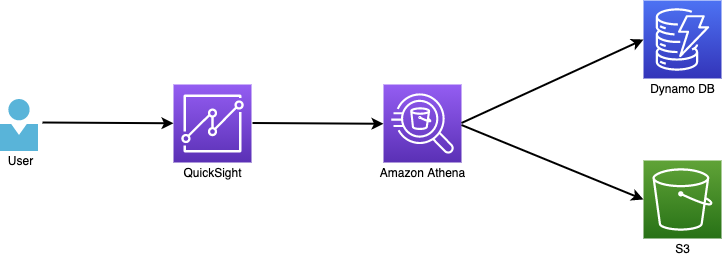
構成図
以下のような構成で検証を行います。
前提・注意点
今回の構成を選んだ前提としてあるのは、ミニマムでサクッと作れるというところを前提としています。
AthenaでDynamoDBをデータソースとして利用する今回の構成では
AthenaがDynamoDBにアクセスする際に、RCUを消費する形になります。
なのでデータ量が多くなった際には、以下の問題が発生する可能性があります。
・RCUの枯渇
・枯渇によりデータがロードできない
・稼働中へのサービスへの影響
上記を考慮すると、DynamoDBのエクスポートを使い、データソースの作成にGlueなどを使うといった方法が
ありますが、Lambdaの作り込みなど工数が大きくなってしまい、ミニマムな構成ではなくなってしまいますので
今回は採択しておりません。それらを考慮した構成は、また別記事で紹介したいと思います。
実際に作っていく
大きく分けて以下の手順で作っていきます。
1.S3バケットの作成
2.Athenaの作成
3.Quicksightの作成
検証で使用している、DynamoDBのテーブルは事前に作成したものを利用しています。
1.S3バケットの作成
Athenaのクエリ結果を保存するためのバケットと、スピルデータを保存するS3バケットを作成します。
今回はバケット名を、
クエリ結果用を[dynamodb-query-test]
スピル用を[spill-dynamodb-query-test]
としています。
2.Athenaの作成
2-1.アクセス用の Lambda 関数を準備する
Fadarated Queryを使ってデータソースを接続するために、アクセス用のLambda関数を作成します。
アクセス用のLambda関数は、すでに用意されているのでそちらを利用します。
Athena > Data Sources > Connect data sourcesにて
「Query a data source」と「Amazon DynamoDB」を選択します。
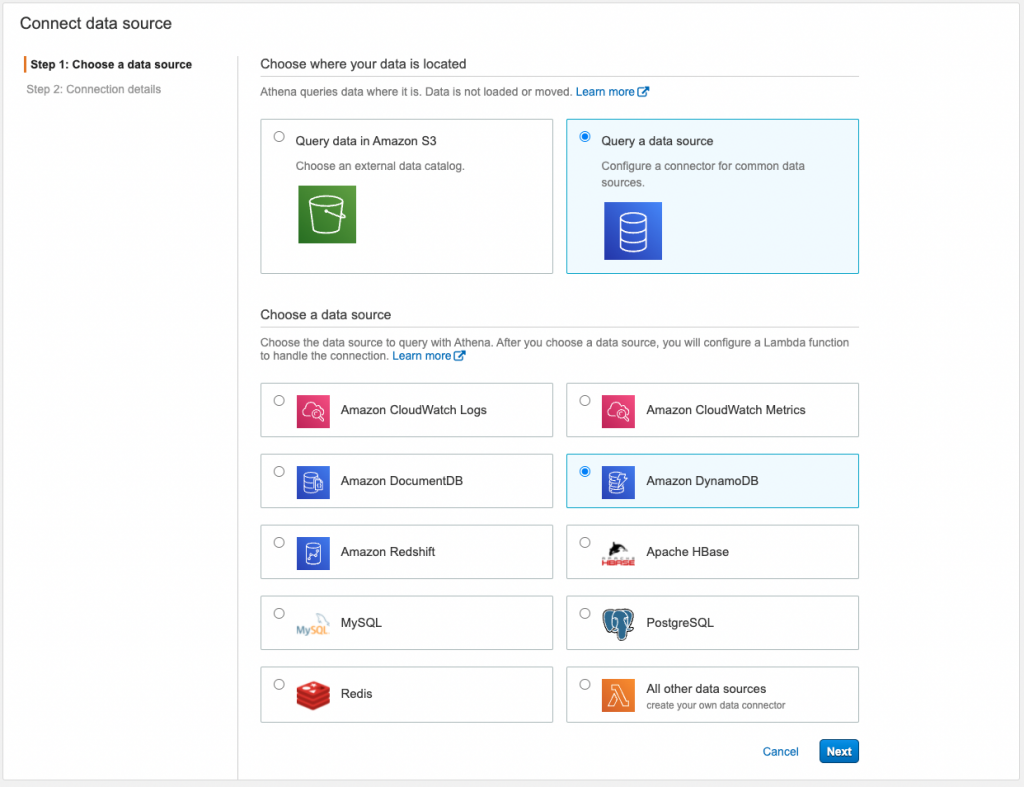
関数の新規作成(Configre new AWS Lambda function)を選択すると
Lambdaの作成画面(アクセス用のLambda関数)に移動します。
ソースコードは以下のリポジトリにあります。
リポジトリ:https://github.com/awslabs/aws-athena-query-federation
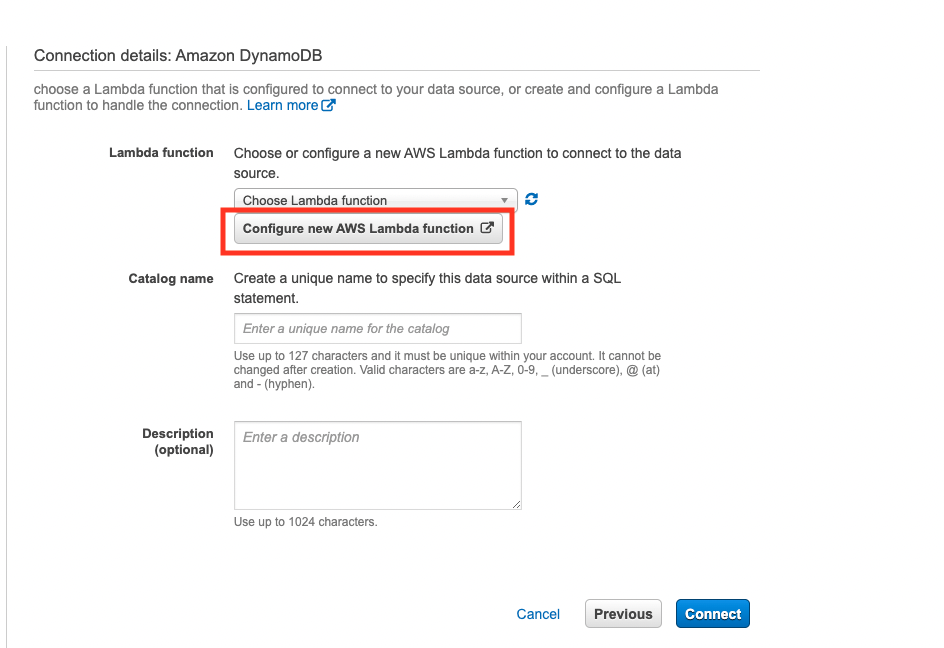
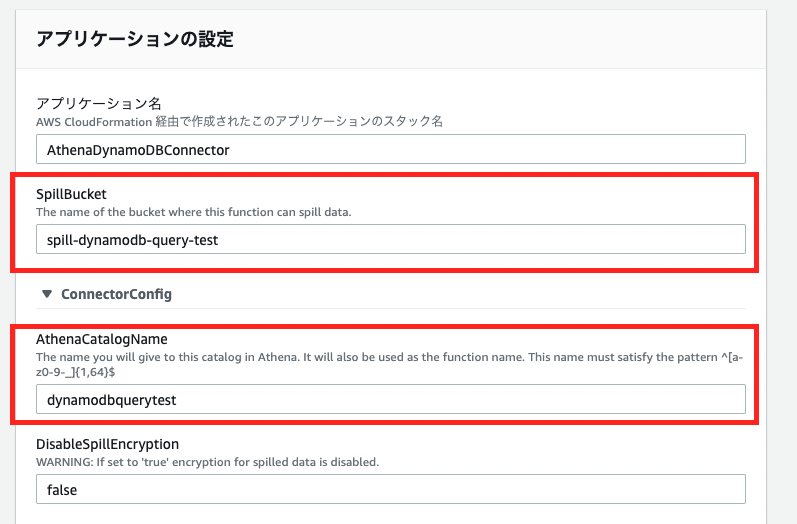
Lambdaの画面では、以下を設定します。
Spill bucket:spill-dynamodb-query-test
Data Catalog:dynamodbquerytest
2-2.データソースの作成
2-1.で作成したLambda関数を使って、データソースを作成します。
Athena > Data Sources > Connect data sourcesにて
「Query a data source」と「Amazon DynamoDB」を選択します。
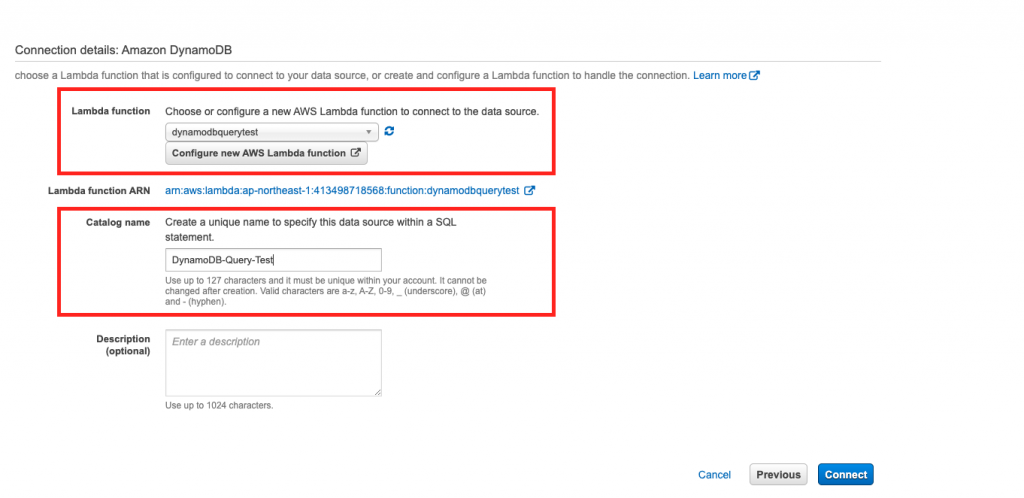
次のページで以下の設定を行います。
Lambda function:dynamodbquerytest
Catalog name:DynamoDB-Query-Test
上記を設定し、[connect]を押下します。
2-3.動作の確認
Fadarated Queryを使ってDynamoDBに接続できるようになったので、試しにクエリを流して、テーブルの内容を確認してみます。
Athena > Query Editorにて、先ほど作成したデータソースを対象にクエリを流します。
Data source: DynamoDB-Query-Test
Database:default
テーブルの全データを取得するクエリを流します。
1SELECT * FROM "DynamoDB-Query-Test"."default"."table1";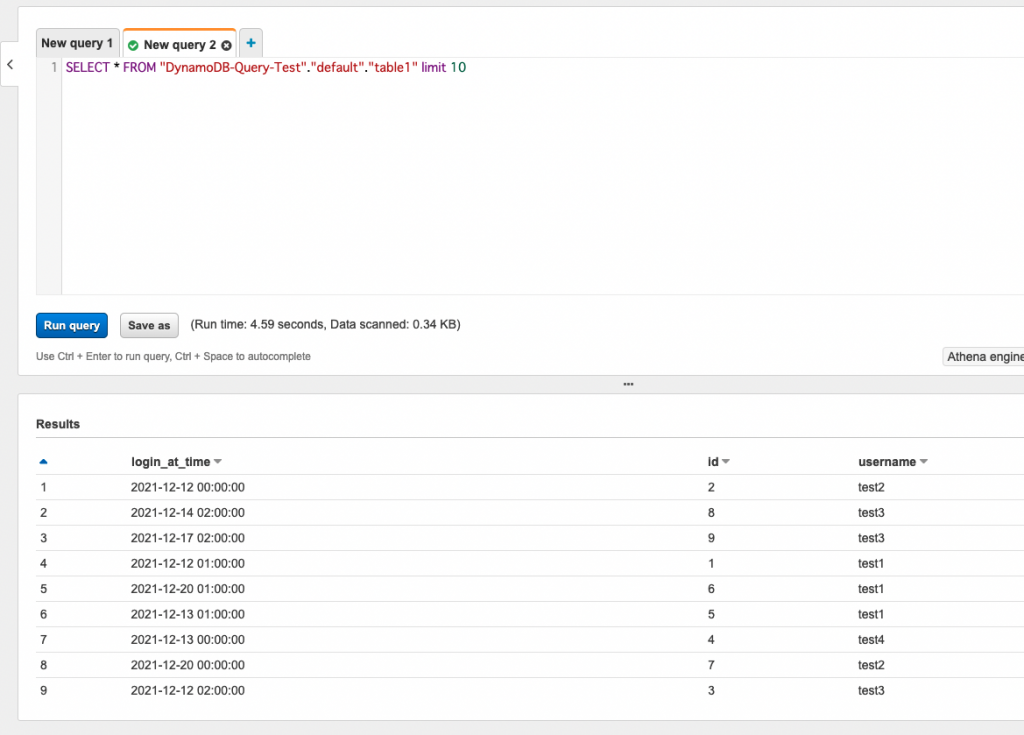
これで、Fadarated Queryを使ってDynamoDBのデータを抽出できるようになりました。
3.Quicksightの作成
Fadarated Queryを使って取得できるようになったDynamoDBのデータをQuicksightで視覚化します。
3-1.Quicksightにログイン
アカウント作成がまだの場合は、サインアップしてください。
Standard Editonであれば30日間の無料トライアルが利用できます。
https://aws.amazon.com/jp/quicksight/pricing/
3-2.アクセス権限の設定
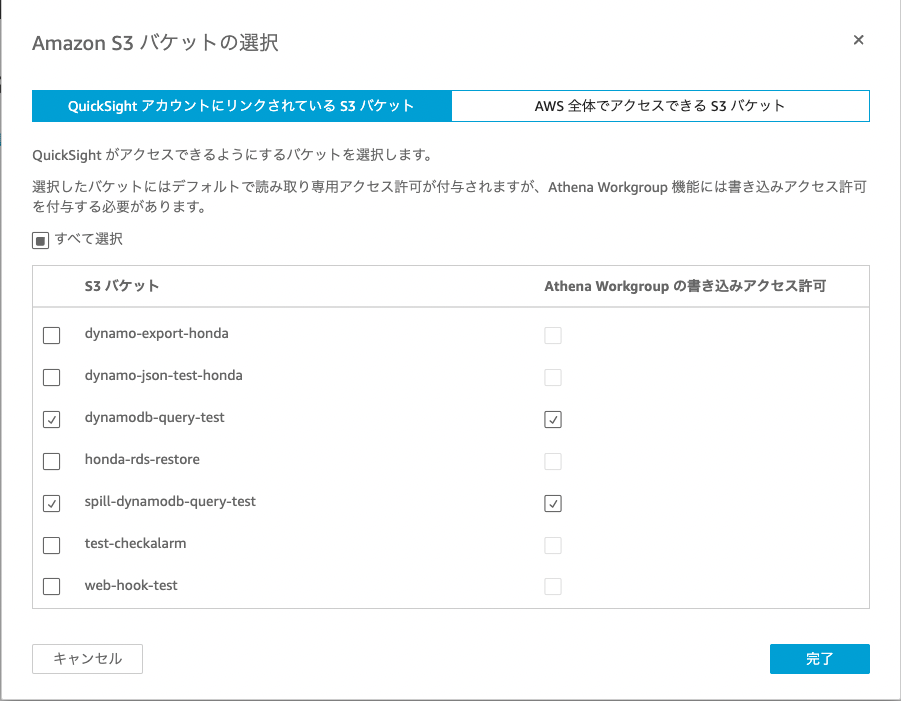
Quicksights > Quicksightの管理 > セキュリティとアクセス権限からアクセス権限を設定します。
S3にチェックを入れ、事前に作成した2つのバケットを許可します。
[dynamodb-query-test]、[spill-dynamodb-query-test]
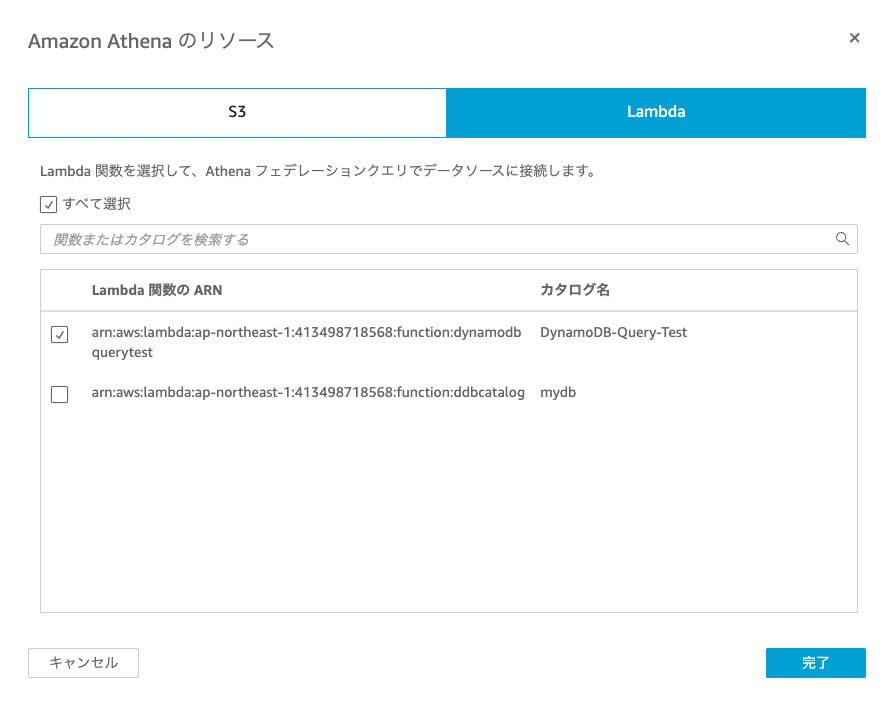
次に、Amazon Athenaにチェックを入れ、Lambdaのタブを選択して
2-1.で作成したLambda関数を選択します
Lambda関数:DynamoDB-Query-Test
3-3.データセットの作成
データセットを作成し、データを可視化します。
データセット > 新しいデータセット > Athena
データソース名:DynamoDB-test
Athena ワークグループ:任意で Athenaにワークグループを変更してください
上記を設定し、データソースを作成します。
テーブルの選択
カタログ: DynamoDB-Query-Test
テーブル:可視化したいテーブルを選択します
「Visualize」を押下すると、選択したテーブルが可視化されます。
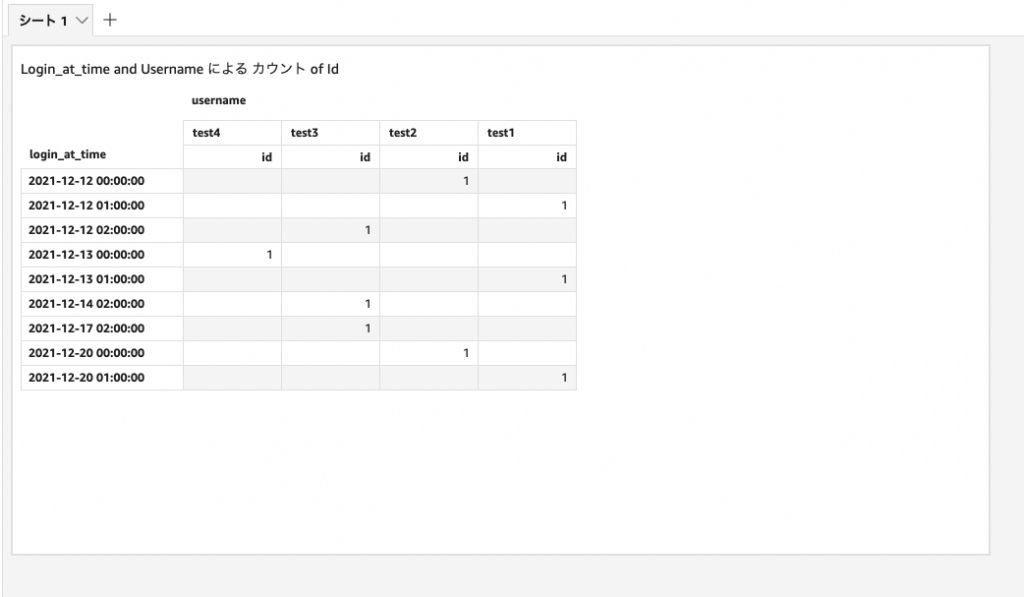
各ユーザーの時間毎のログイン履歴のようなデータを可視化してみました。
カスタムクエリを使うことで、複数のテーブルを組み合わせてデータセットを作成することもできます。
最後に
本当にミニマムな構成でサクッと可視化をしてみるというこういう手順でできそうです。ただ冒頭にも書きましたが、実運用になるとDynamoDBへの負荷など考慮するところが多くなるので、その点ご留意いただければと思います。
Quicksightでのデータ可視化ライフを楽しんでください!!
